Selenium 第一次是從書看到的 (網站擷取|使用Python) 這本
書上寫的蠻詳細的,但我當時對python還是初心者,現在大概是新手等級(沒差多少)
Selenium是一種自動化整合工具 ,然後可以用來爬網頁資料
現在來記錄一下順便實作
第一步當然要先 安裝selenium 套件
安裝完後因為它是屬於自動化的網頁擷取套件,說道自動化我們當然要先控制瀏覽器
於是到官網載相關的驅動 driver !
!
點選download會到這一頁,選擇要用的瀏覽器,這邊是用chrome 作為範例
https://www.seleniumhq.org/download/
https://ithelp.ithome.com.tw/upload/images/20190906/20103516tsadgf16x7.jpg
首先當然是要先介紹一下 單純只用request 與BeautifulSoup套件所使用的爬蟲
從網頁上按下F12可以看到HTML的標籤,透過標籤可以找到對應關連與屬性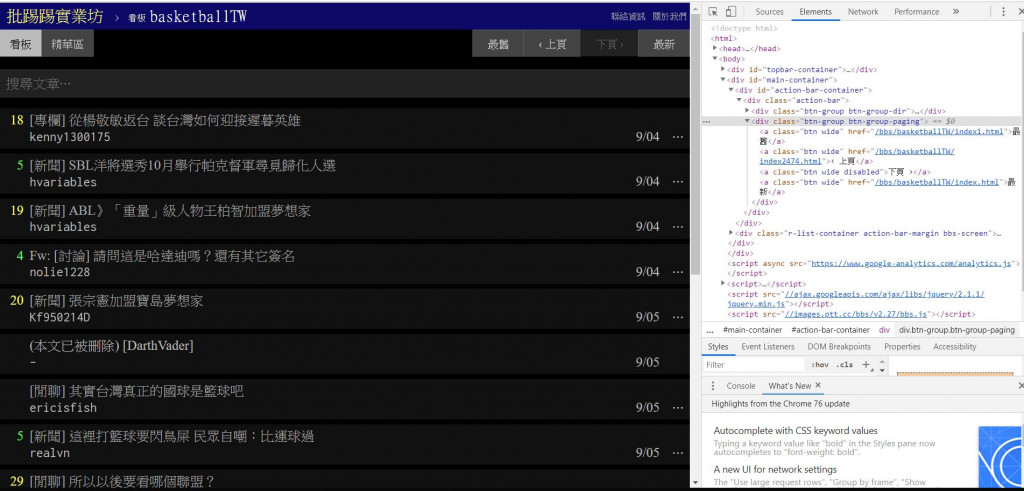
這裡有一個簡單的範例,詳細可以參考去年的鐵人賽有位大大的文章也寫的挺好
https://ithelp.ithome.com.tw/articles/10204709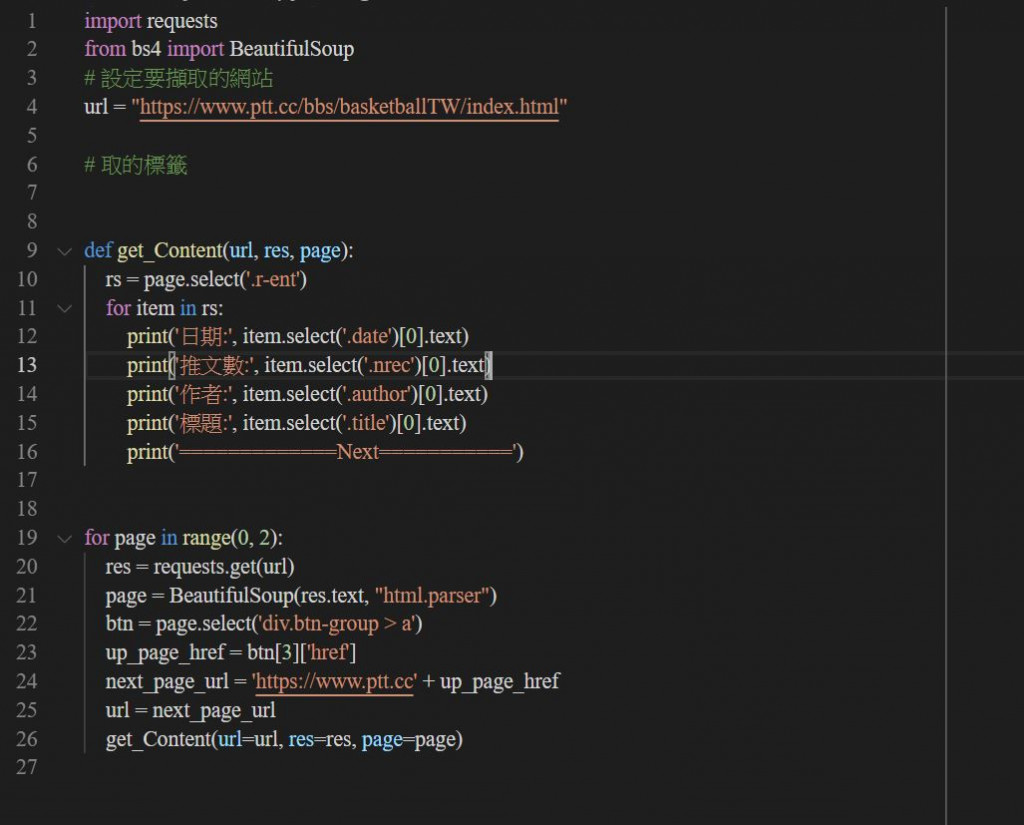
透過取得標籤 跟對應的標籤序列我們可以間單爬幾頁資料
資料內容可以將常看到的 作者、標題、日期、推文數可爬下來
回歸正題 那怎麼要做自動化爬蟲!
明日待續


 iThome鐵人賽
iThome鐵人賽
{kind=link}